
Umi-OCR是一个完全开源的文字识别工具,它在GitHub上免费提供。此工具利用先进的深度学习和计算机视觉技术,能迅速从图像中提取文字并转换为可编辑的文本格式。无论是手机拍照、扫描文档还是其他图像来源,Umi-OCR都能高效进行文字识别。
OCR技术简介
光学字符识别(OCR)技术使得从纸质文档到电子文本的转换成为可能。Umi-OCR基于深度学习增强了这一流程,提高了处理速度和识别准确性,支持多种语言,适用于广泛的应用场景。
Umi-OCR的主要优势
- 高准确性:深度学习模型确保即使在图像质量不佳或文字扭曲的情况下也能高精度识别。
- 快速处理:利用多线程技术,Umi-OCR可以快速处理大量文档。
功能特点
- 开源免费:在GitHub上完全开放源代码。
- 离线运行:无需互联网连接,下载后即可使用。
- 用户友好:界面简洁明了,易于操作。
- 多语言支持:支持中文、英文、日文、韩文等多达99种语言。
- 高效率:支持批量处理,提高工作效率。
- 二维码功能:不仅支持文字识别,还能识别和生成二维码。
实际应用场景
- 数字化文档:转换纸质文件为电子文本,提升存储与检索效率。
- 自动数据录入:从发票和表格中提取数据,减少手动录入。
- 跨语言图片翻译:方便用户理解和交流不同语言的文本。
- 快速识别个人信息:如身份证和名片的文本提取。
最新版本 V2.1.2 更新亮点
- 新增批量任务的暂停与恢复功能。
- 支持保存为单层纯文本PDF。
- 扩展HTTP接口功能,增加自定义设置。
- 命令行增强,支持指定截图区域。
- 性能和界面优化,提升用户体验。
Umi-OCR不仅功能全面,操作简便,还能高效处理各类文字识别任务,是您理想的文字识别解决方案。
Umi-OCR 软件功能界面
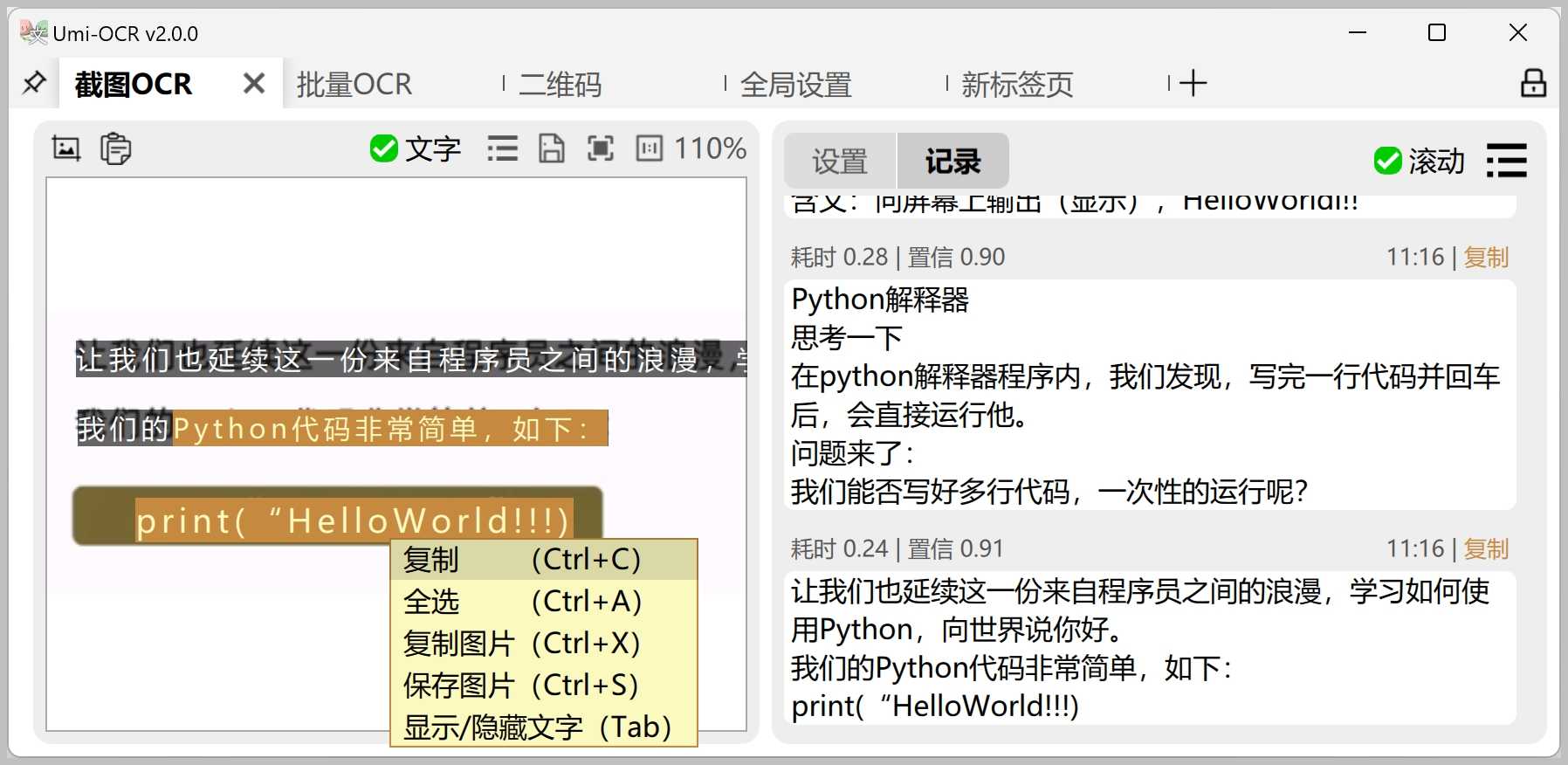
截图OCR
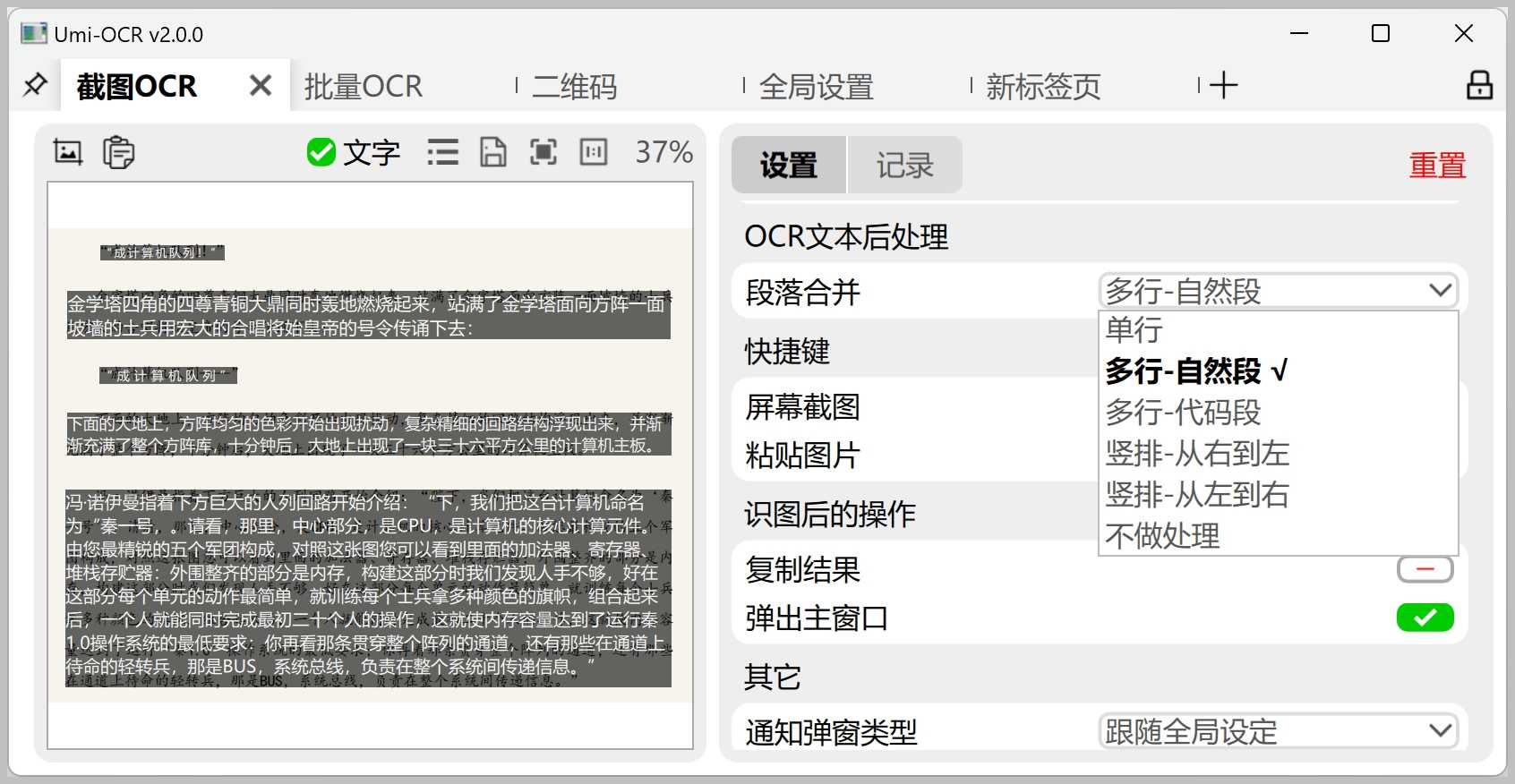
文本后处理
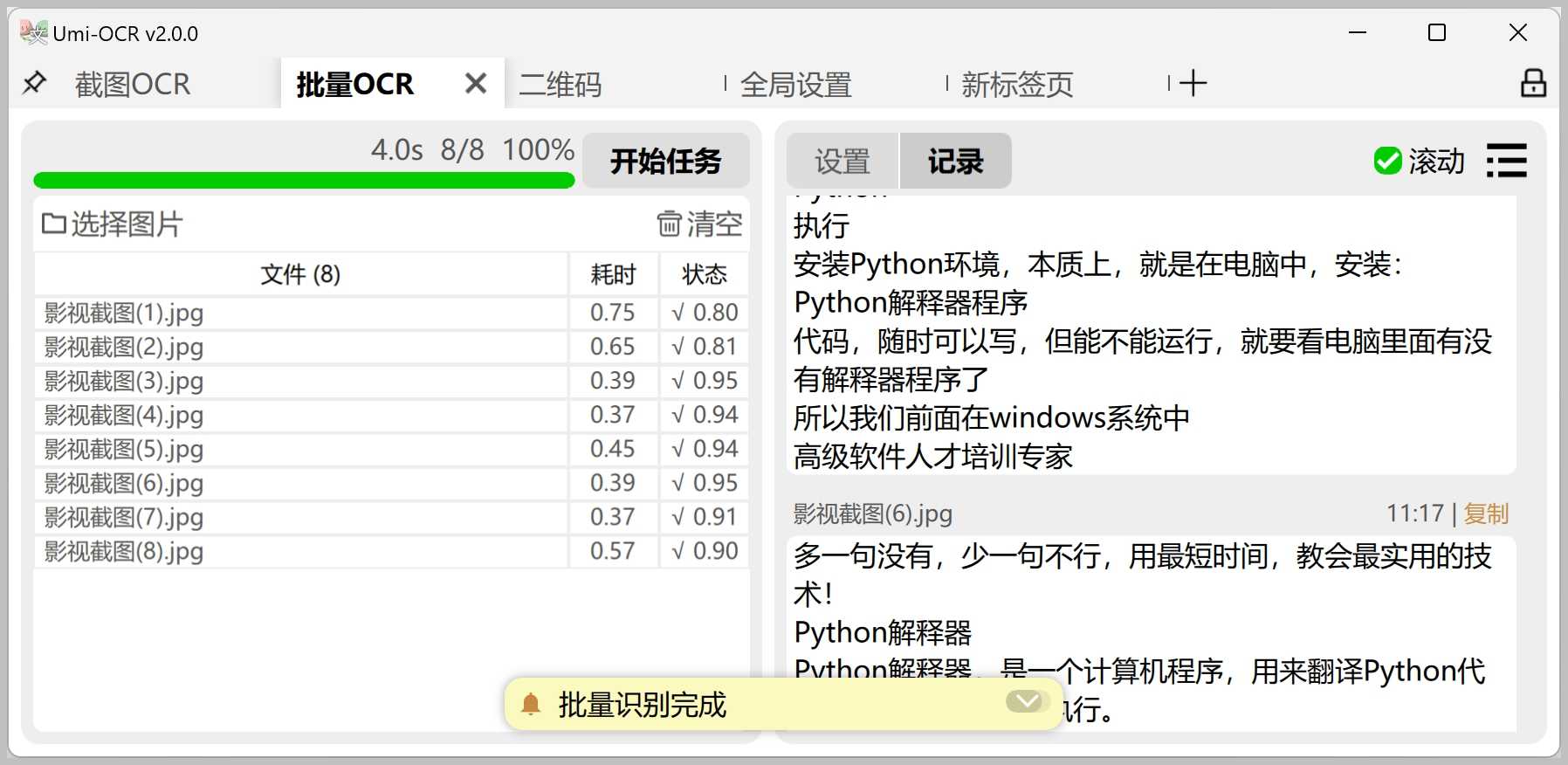
批量OCR
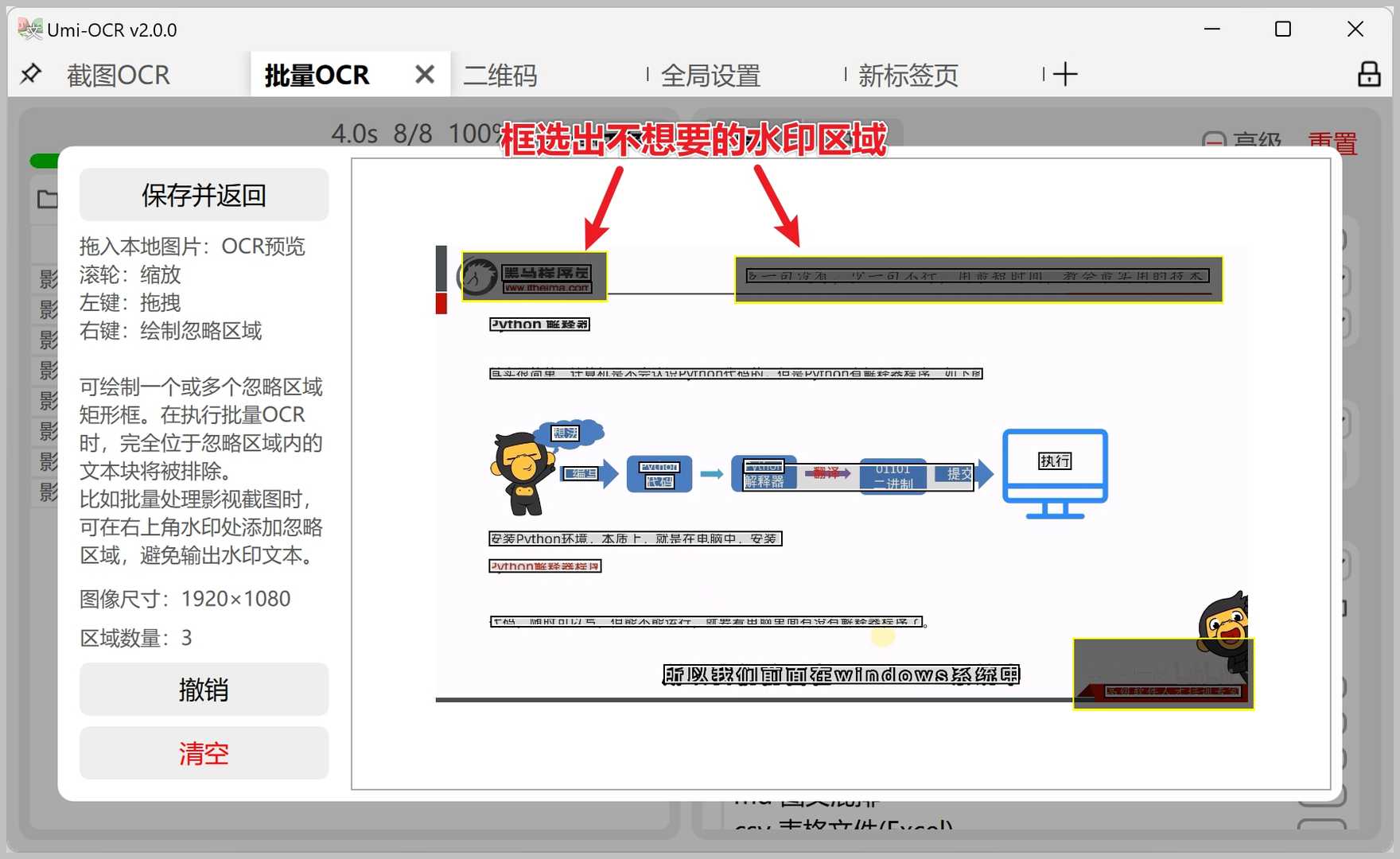
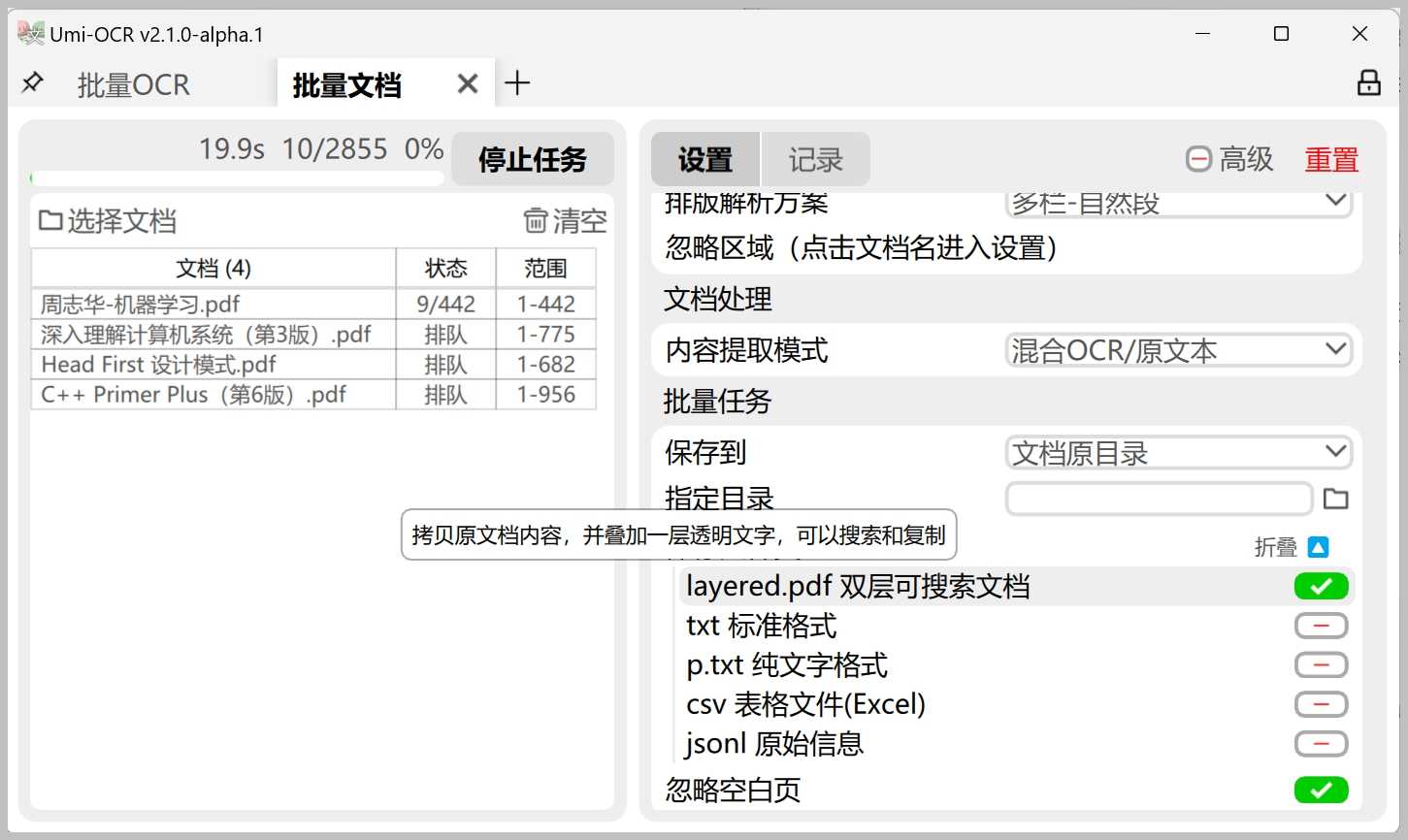
文档识别
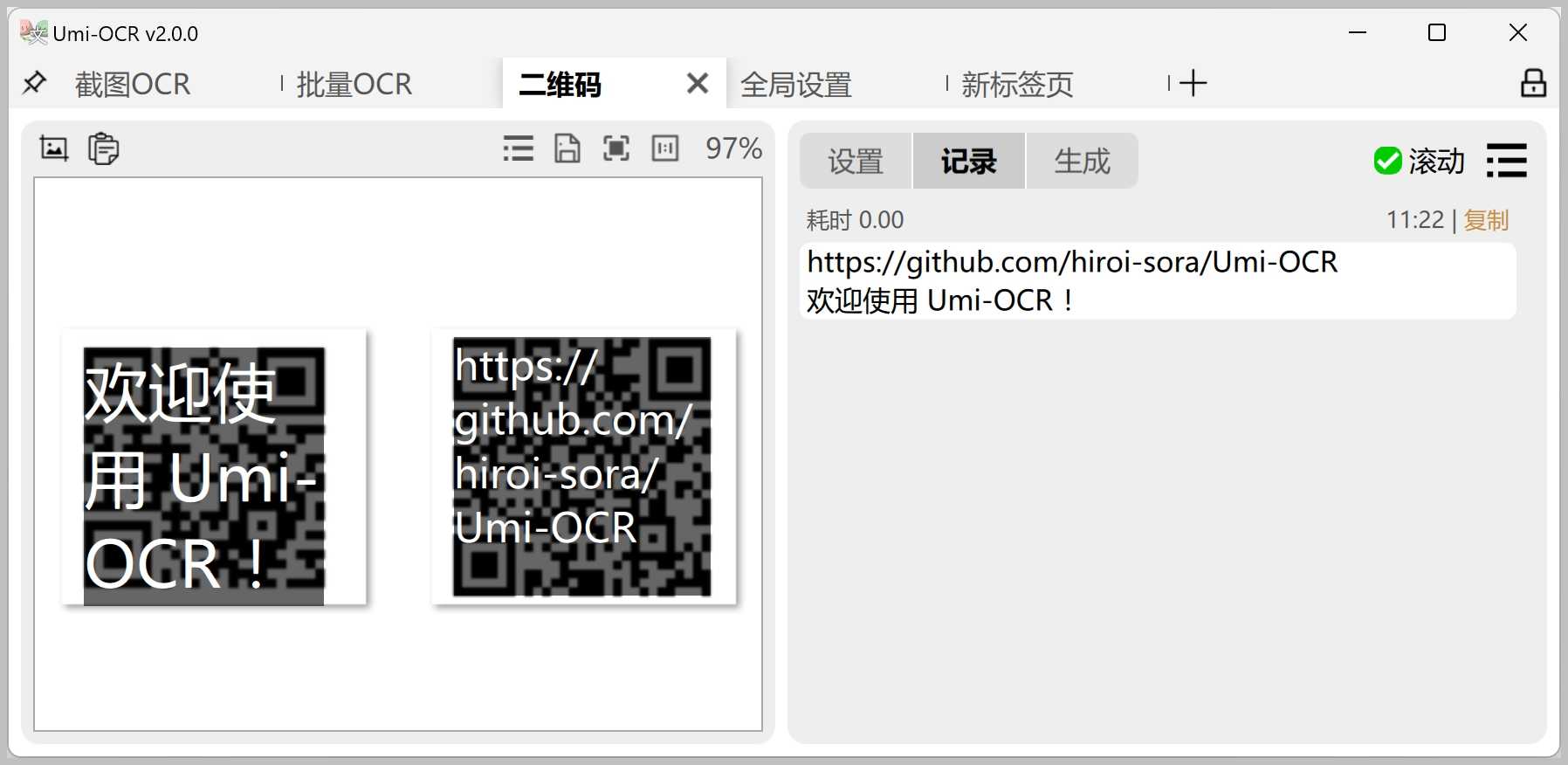
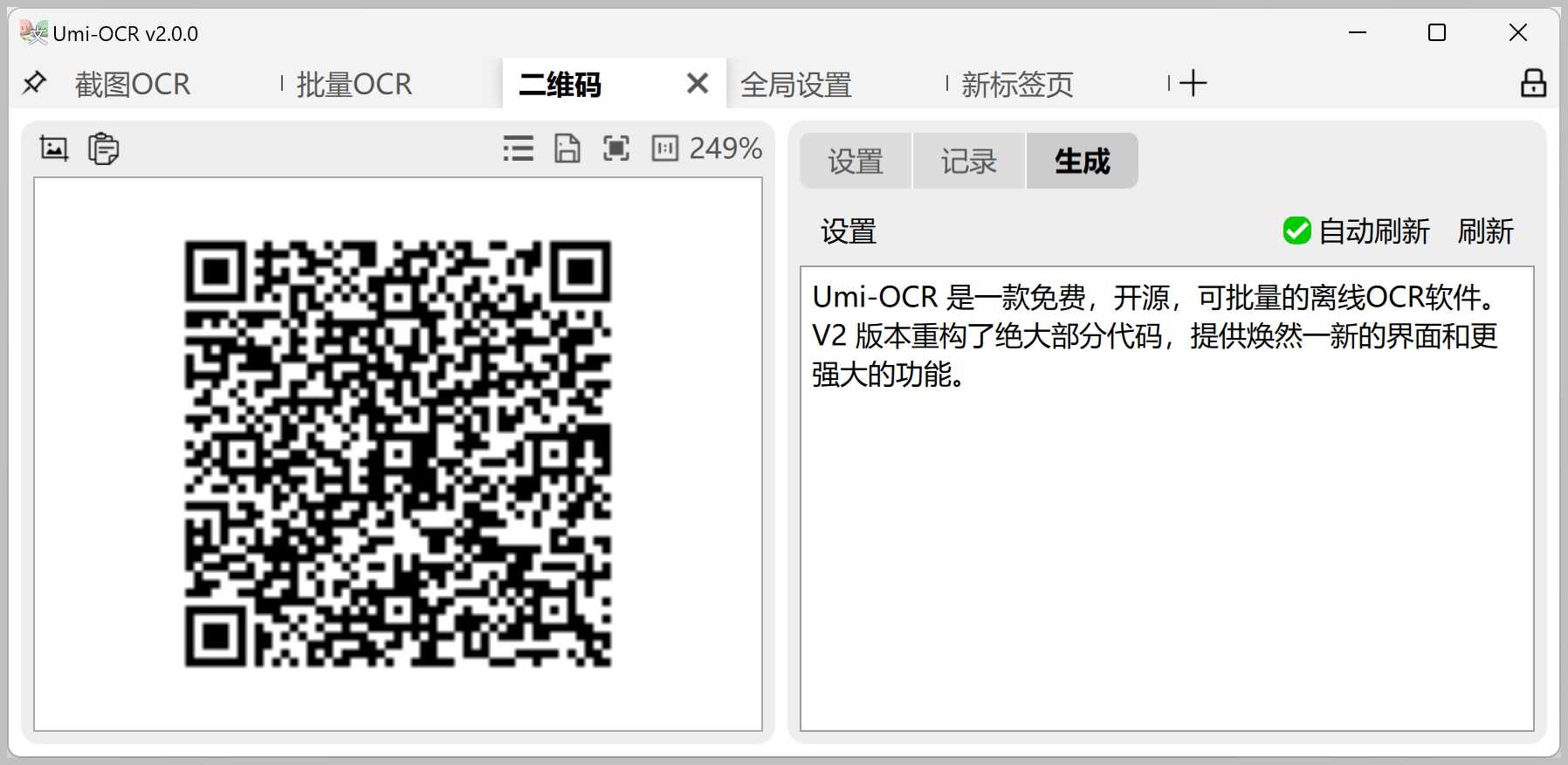
二维码识别与生成
界面语言更改
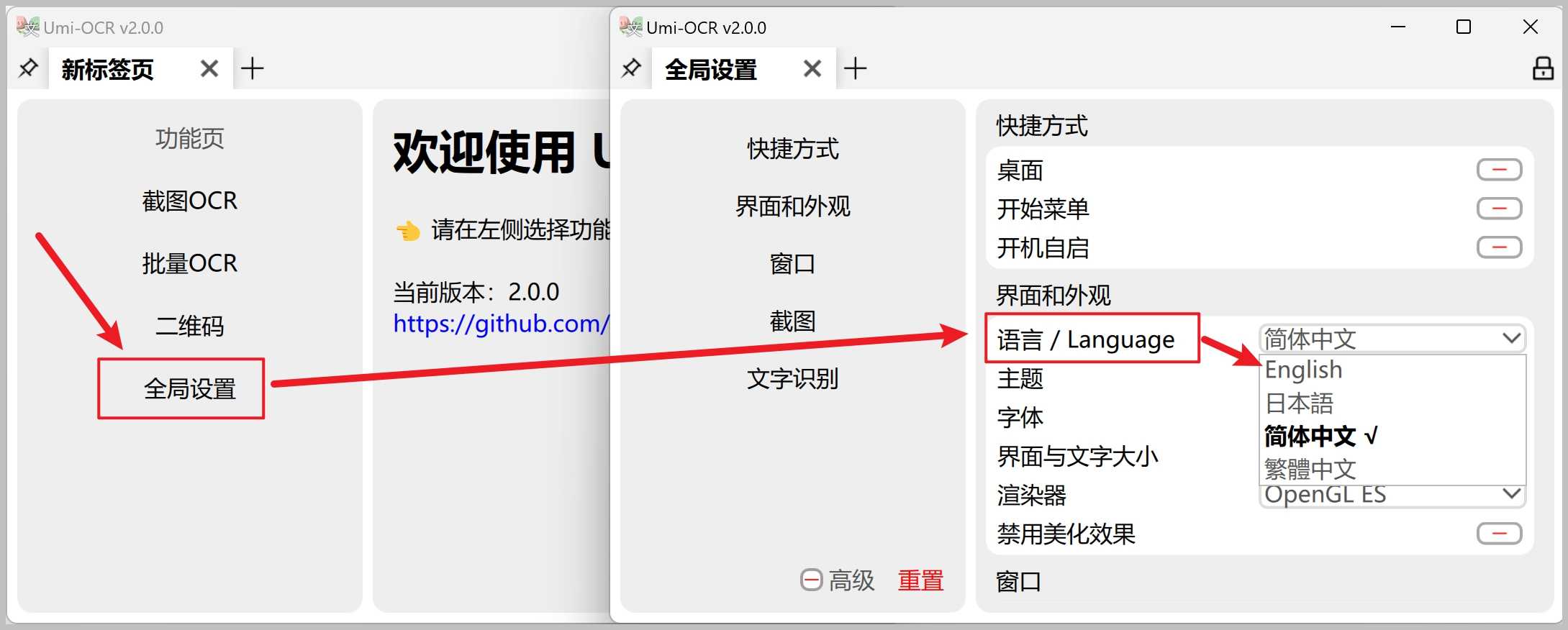
全局设置
免责声明:本站所有资源均收集自互联网,分享目的仅供学习参考,并不贩卖资源,资源版权归该资源的合法拥有者所有,请您在下载后24小时内删除。若本站发布的内容侵犯到您的合法权益,请立即联系43404810@qq.com及时做删除处理!

