
EchoMimic 是由阿里巴巴达摩院研发的一项先进AI技术,它能够通过音频文件和一张面部照片,自动生成与音频内容完美同步的口型动画视频。这项技术广泛应用于娱乐、教育、虚拟现实和在线会议等多个领域,为用户带来创新性的体验。
目前,EchoMimic V2版本已经推出,新版本支持上传半身照片,可生成更生动的半身数字人,让应用场景更加多样化。
主要功能
– 精准口型同步
通过分析音频内容和面部特征点,生成与语音节奏和内容完全匹配的视频效果。
– 自然逼真的动画
技术支持自然的面部运动和表情变化,生成的动画真实感强,接近真人表现。
– 多语言与多风格支持
无论是普通话、英语还是歌唱风格,EchoMimic 都能实现高质量的同步效果,满足多元化需求。
适用场景
– 娱乐领域
为电影、电视、游戏中的角色生成同步对话动画,提升观众沉浸感。
– 教育行业
制作互动教学视频,让学习变得生动有趣,提高教育质量。
– 虚拟现实 (VR)
生成逼真的虚拟角色动画,增强用户在VR环境中的沉浸体验。
– 在线会议
为远程会议生成同步口型动画,提升交流的真实感。
– 增强现实 (AR)
在AR应用中打造栩栩如生的虚拟人物,丰富互动体验。
系统配置要求
– 操作系统:Windows 10/11 64位
– 显卡要求:
– V1版本:至少8G显存的 NVIDIA 显卡
– V2版本:至少12G显存,推荐16G或以上显存以保证稳定运行(显卡性能越强,生成速度越快)
– 软件依赖:CUDA ≥ 12.4
– 存储空间:解压后约需19.8G空间
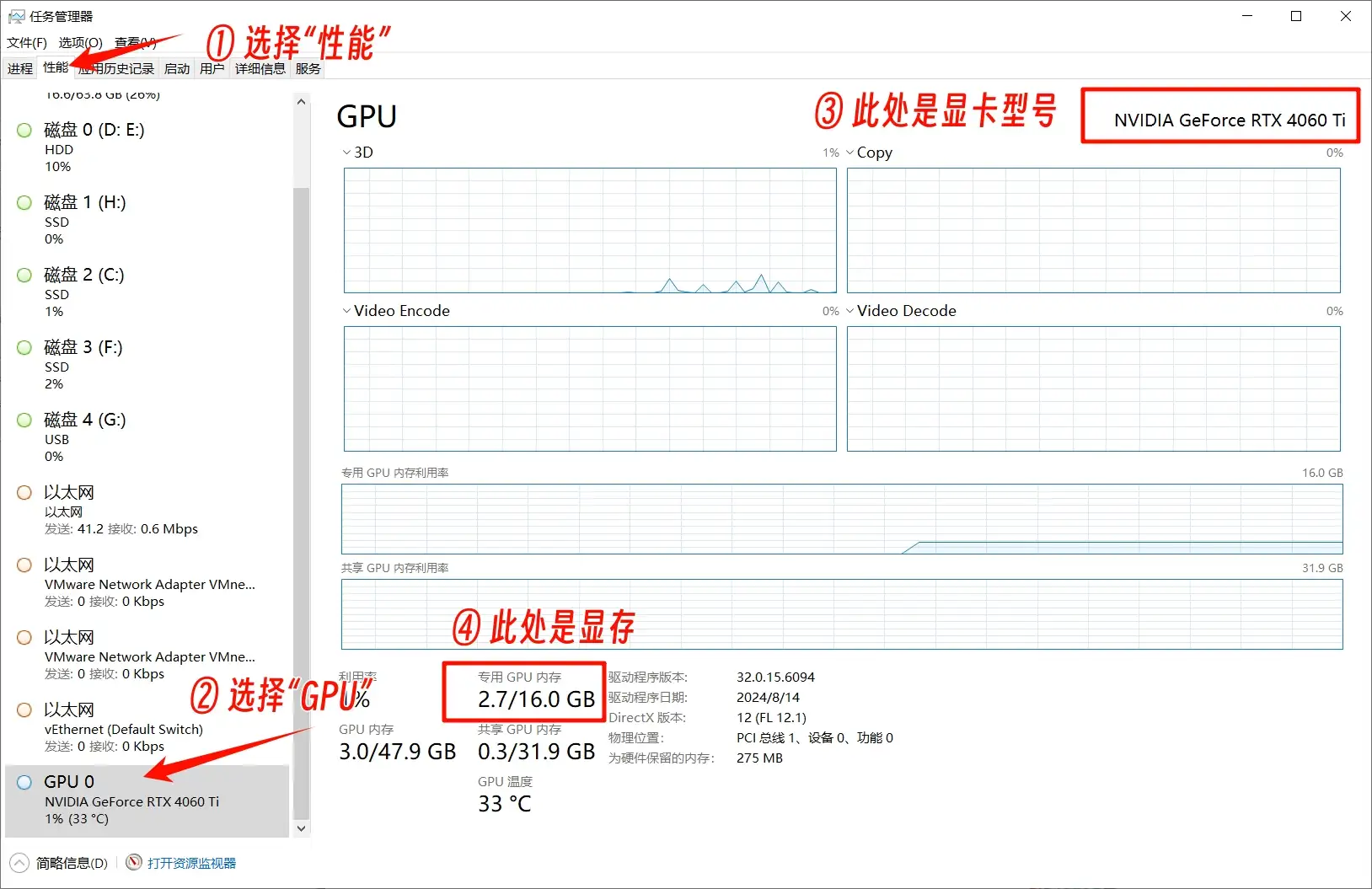
– 显卡信息查看方法:
1. 打开任务管理器
2. 点击“性能”选项卡
3. 在“GPU”区域查看显卡型号和显存大小
详细的 CUDA 安装教程请访问:[https://www.rjgcz.com/10135.html](https://www.rjgcz.com/10135.html)
使用教程
V2版本操作指南
1. 解压下载的整合包,确保文件夹及文件名无中文字符(包括图片、音频等文件)。

2. 双击“一键启动.exe”,稍等片刻,浏览器会自动打开操作界面。

3. 上传1:1比例正方形的人物正脸照片,确保五官清晰、素材符合要求(参考页面底部示例)。
4. 上传音频文件,建议使用纯人声音频,去除背景音乐。
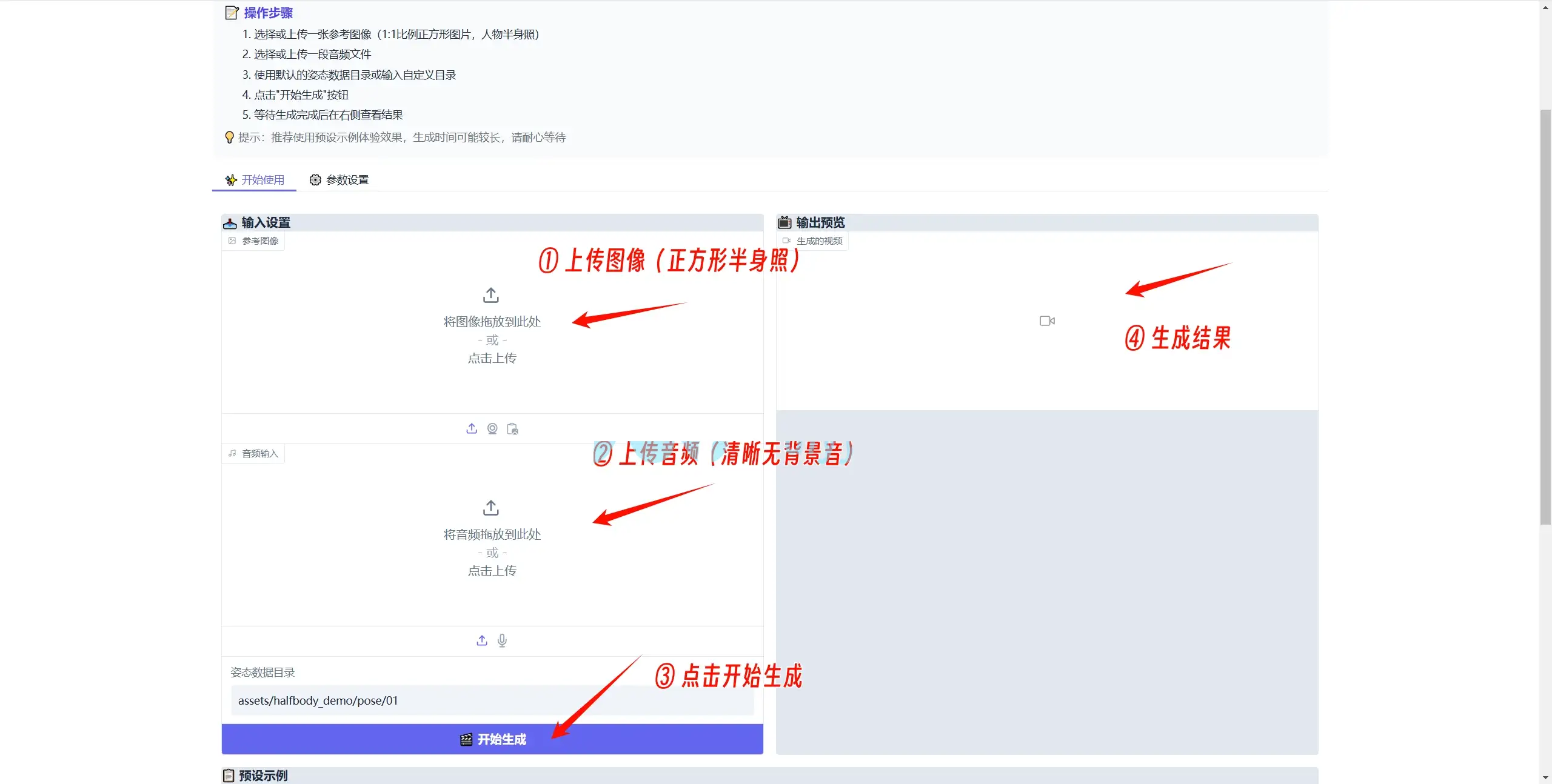
5. 点击“开始生成”,耐心等待生成完成(例如:4060Ti 16G 显卡,生成1秒视频需约5分钟)。
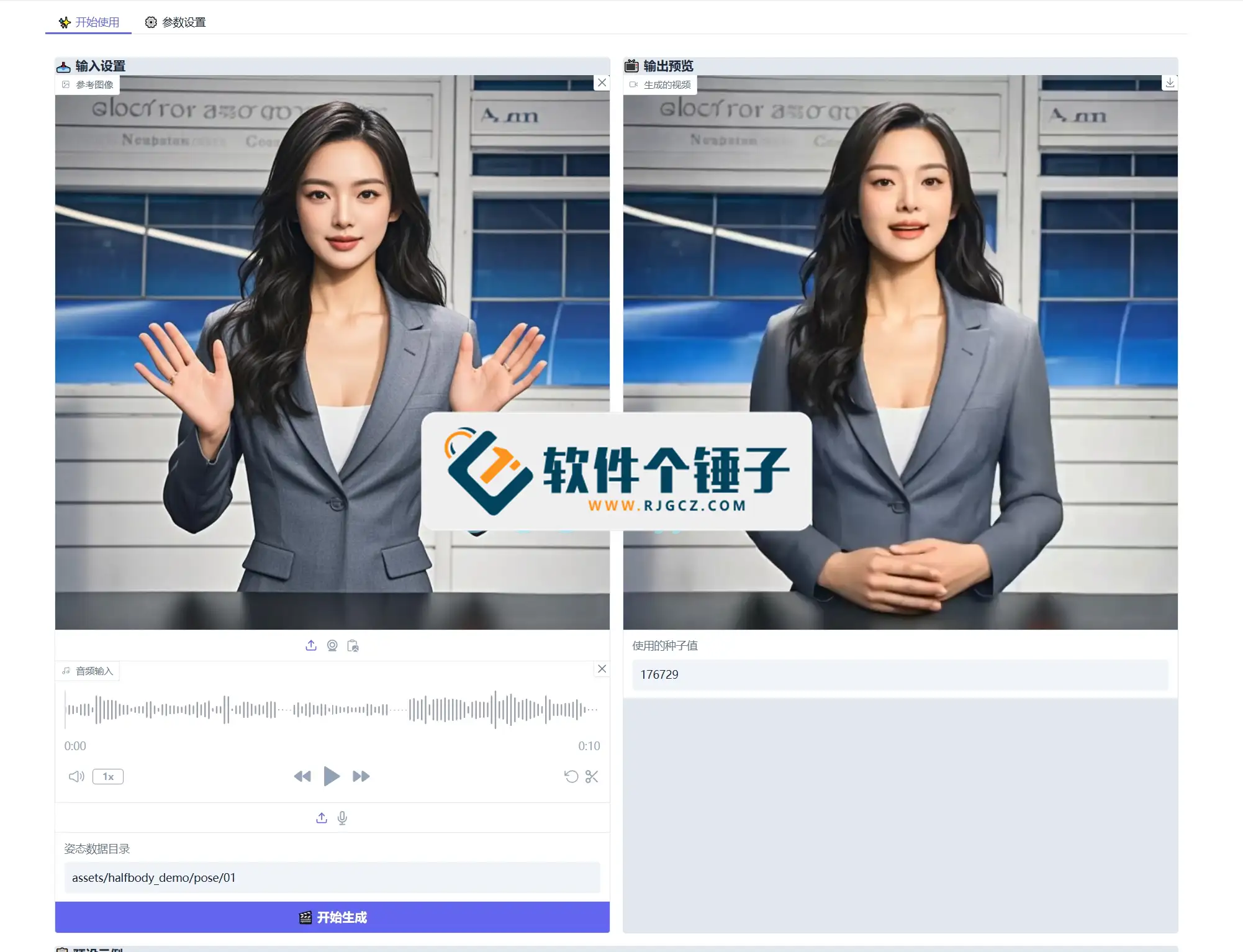
6. 生成完成后可预览并保存视频。
V1版本操作指南
1. 解压后双击“一键启动.exe”,打开浏览器操作界面。
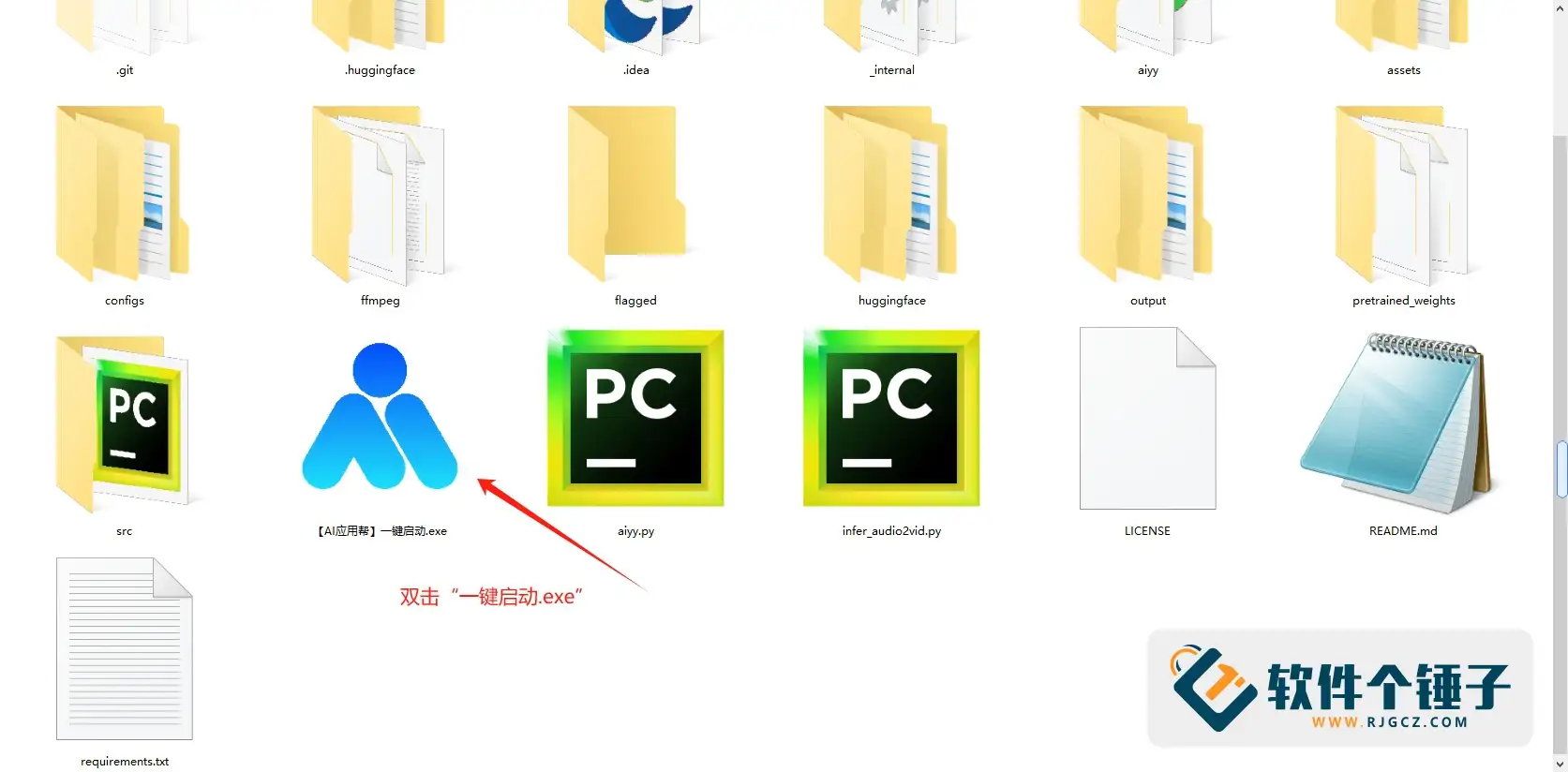
2. 上传人脸照片和音频文件,调整参数(如视频长度,默认为50秒以内)或使用默认设置。
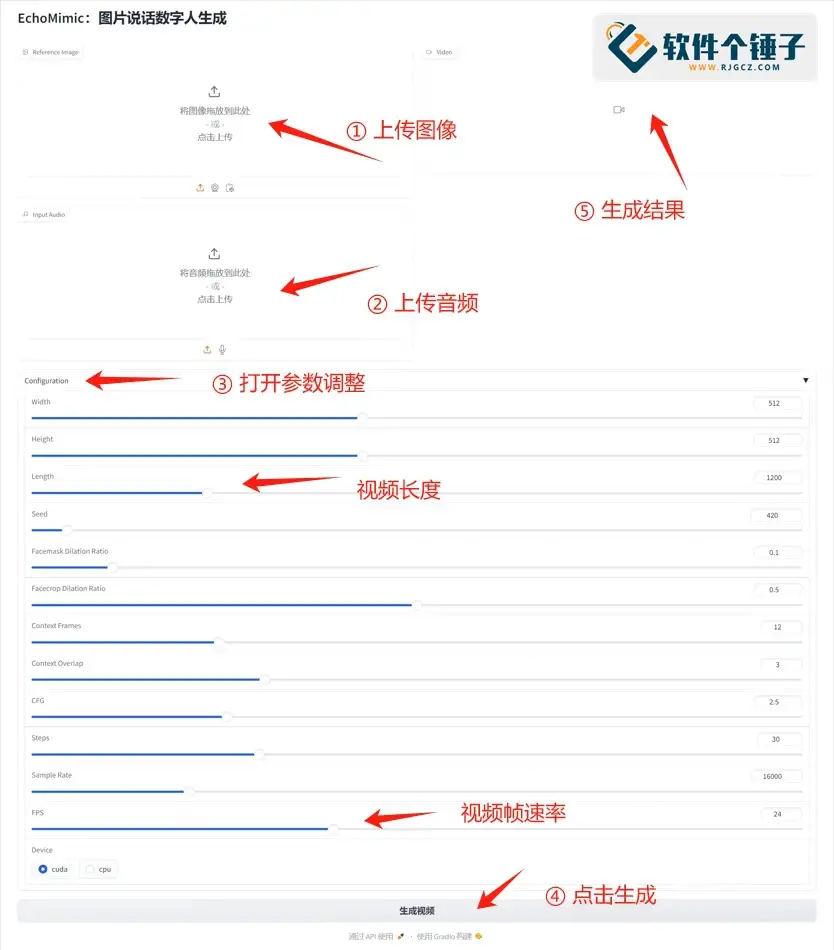
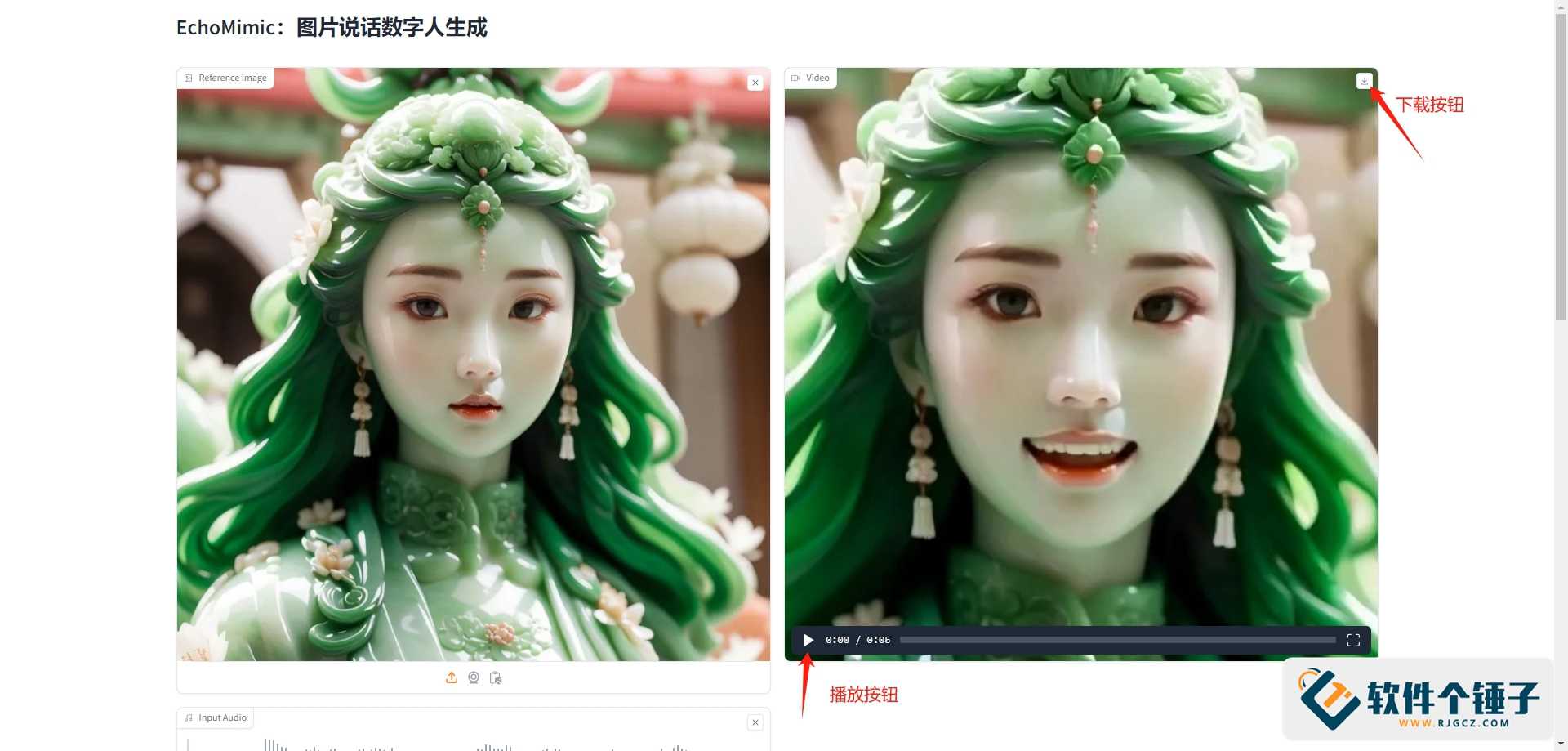
3. 点击“提交”,生成结果显示在右侧,可预览并下载。
注意:无论使用哪个版本,确保文件路径及名称无中文字符,以避免软件识别错误。
官方案例展示:
开源地址
– V1版本:[https://github.com/BadToBest/EchoMimic](https://github.com/BadToBest/EchoMimic)
– V2版本:[https://github.com/antgroup/echomimic_v2](https://github.com/antgroup/echomimic_v2)

